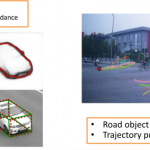
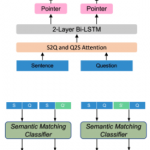
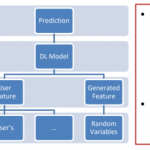
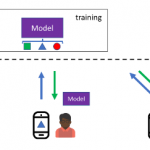
DeepSLAM project is designed to develop an end-to-end and all-in-one deep neural network capable of followings, simultaneously, with only road scene RGB images
(a) Object Detection using RGB images and videos;
(b) Object Re-identification over multiple frames, with occlusions;
(c) Predicting multiple object’s future trajectories.
This all-in-one solution provides a better level of information integrity and reuse. In doing so, a local belief of the surrounding area will be trained with grid cells, a navigation system in humans’ brain, to generate a local implicit map to capture dynamic road condition. Then local coarse implicit mapping is then combined with global accurate road information for above three goals.
F2-T DeepSLAM: Object Detection, Re-identification and Prediction wih Implicit Mapping