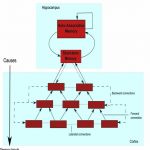
This project aims at creating deep architectures inspired by cognitive sciences to under visual scenes either in images or videos. The characteristic of the proposed architecture is that it simplifies the inference using biological plausible marginals (object type and spatial location), which can be learned in an unsupervised way directly from data (i.e. without labels).
F1-M Bidirectional Deep Learning Architecture for Scene Understanding