PI: Jose Principe
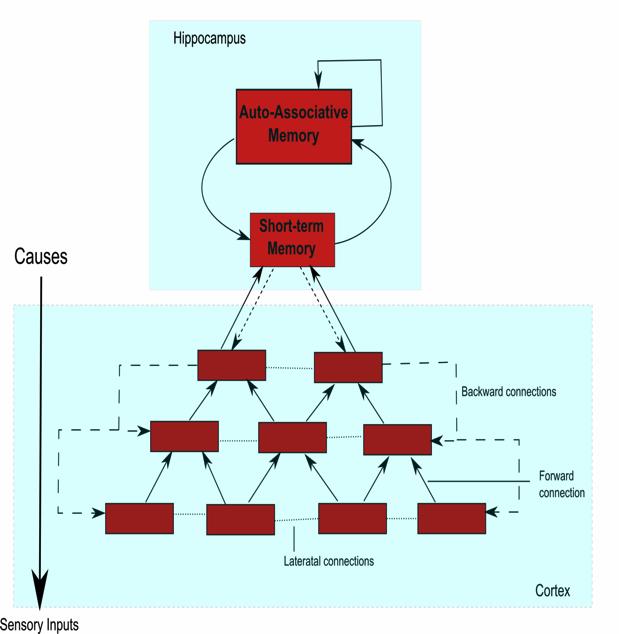
This project aims at creating deep architectures inspired by cognitive sciences to under visual scenes either in images or videos. The characteristic of the proposed architecture is that it simplifies the inference using biological plausible marginals (object type and spatial location), which can be learned in an unsupervised way directly from data (i.e. without labels). The objects extracted from the flow of time are also organized in an external memory, such that they can reused in future inferences, once the system experiments the outcomes of the inferences through reinforcement learning. This is not a traditional deep learning architecture, which can be retrained without losing past information as required for industrial applications.
The characteristics of the design (based on dynamical models, distributed and hierarchical processing) make it very appropriate for a large class of applications involving streaming data or static databases. A preliminary version of the overall architecture is available, which can be configured for customer applications.